

Compartir conocimiento es clave para la ciencia. Nos permite construir, avanzar y descubrir nuevos paradigmas. Pero ¿cómo se comparte la información personal en el mundo de la salud y la atención médica? ¿Qué protocolos existen para garantizar la anonimidad y protección de los datos necesarios de una investigación y especialmente, de datos genómicos? ¿Son realmente anónimos?
Henrietta Lacks y su línea celular inmortal: ¿un problema de anonimato?
Las células HeLa gozan de renombre a nivel global en el ámbito de la investigación científica. Pertenecen al grupo de células de cultivo celular y representan el linaje humano más antiguo y ampliamente empleado en investigación. No obstante, su origen es singular. Esta línea celular procede de una muestra de cáncer uterino de la paciente Henrietta Lacks, quien estaba siendo tratada en el Hospital Johns Hopkins en 1951. Estas células, conocidas como HeLa por las iniciales de la paciente, marcaron el primer logro de reproducción celular en entornos de laboratorio, mostrando un crecimiento sostenido bajo las condiciones adecuadas. Este fenómeno dio lugar al término "células inmortales", debido a su capacidad de proliferar indefinidamente.
Tan extraordinaria era y es esta característica, que el Hospital Johns Hopkins. la aprovechó y empezo a utilizar los cultivos de estas células para la investigación. Eran los años cincuenta y en aquel entonces no se le pidió ningún tipo de consentimiento a Henrietta Lacks. Lo que actualmente supondría un grave problema de anonimato en aquel momento no se tenía en cuenta. Tal fue el exito del uso de las células HeLa en investigación, que se acabaron comercializando. No fue hasta cincuenta años más tarde que la familia se enteraría de todo lo que había sucedido, por un trabajo periodístico realizado por Rebeca Skloot, que escribiría el libro “La vida inmortal de Henrietta Lacks”.
En 2013, se publicó el genoma y transcriptoma de las células Hela. Como en un principio era una línia cel·lular no personal, se publicó en un servidor de datos científicos público. Rebeca Skloot se enteró y publicó un artículo en el The New York Times, como secuela del libro, denunciándolo. Inmediatamente, el National Institute of Health reaccionó y retiró esos datos del servidor público y los puso en un servidor de acceso controlado, el llamado dbGaP.
Acceso controlado a miles y miles de datos genómicos
En Europa dos años más tarde, se creó también un archivo de acceso controlado, llamado Archivo Europeo Genoma-Fenoma (EGA) donde actualmente hay más de 3.300 estudios y alrededor de 8.000 datasets (la línea celular HeLa representa un solo dataset). La EGA, tiene dos sedes: el European Bioinformatics Institute (EBI) en Cambridge y el Centre for Genomic Regulation (CRG) en Barcelona, que cuenta con apoyo del Barcelona Supercomputing Center (BSC-CNS).
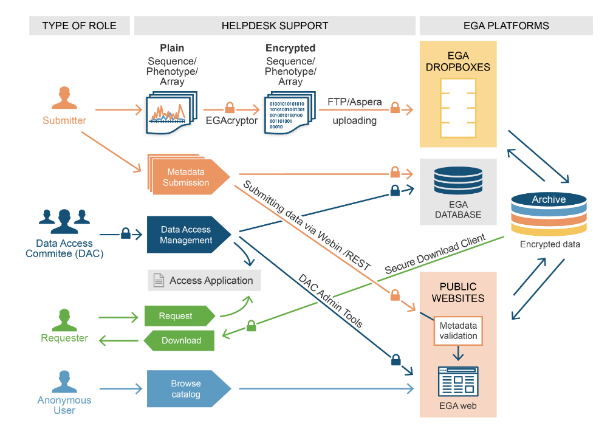
Figura 1. Archivo Europeo Genoma-Fenoma
Pero, ¿cúal es su función? El Archivo Europeo Genoma-fenoma es el servicio europeo para el archivo permanente y el intercambio de datos genéticos, fenotípicos y clínicos de identificación personal, generados con fines de proyectos de investigación biomédica, o en el contexto de sistemas de atención médica centrados en la investigación.
- La información proviene de centros de investigación e instituciones de salud
- Es de acesso controlado por los comités de Data Access
- Los usuarios son investigadores de otras instituciones de investigación en salud
Tiene más de 1.600 comités de acceso y cada uno da acceso, o no, a sus datos. Hay unos 1.800 grupos de trabajo que han enviado datos y unos 21.000 investigadores que los han recibido. En total, más de 4 millones de ficheros y 15 petabytes de datos triplicados (45 petabytes de datos). Para ponerlo fácil, si un ordenador tiene medio terabyte, esta información representaría unos 30.000 ordenadores y si triplicamos, unos 90.000.
Muchos más datos genómicos por descubrir
Con tantos estudios disponibles en el EGA podemos pensar ¿es necesario realizar más? Proyectos de análisis genómico como el BRCA Exhange, auspiciado por la asociación Global Alliance Health y que se centra en recoger y estudiar las mutaciones de tan solo dos genes relacionados principalmente con el cáncer de mama hereditario (del 90% de las mutaciones recogidas en estos dos genes, no hay evidencia de su función u origen), demuestran que todavía hay muchos datos para analizar e interpretar.
En esta imagen, se recogen diferentes proyectos de análisis genómico poblacionales (no por enfermedad sino buscando directamente en población). Son estudios poblacionales, porque la forma de saber si las variantes genómicas son potencialmente benignas o malignas (mutaciones), es a base de recopilar información sobre qué variantes o mutaciones tiene la población (secuenciando tantas personas como sea posible) y cuáles están relacionadas con algún tipo de enfermedad o de condición (a lo mejor es la altura, el color de los ojos, el peso, etc…).
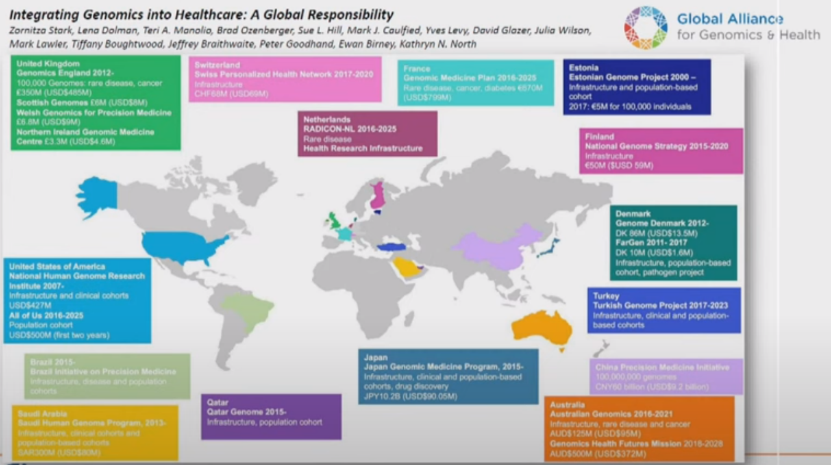
Figura2. Figura del 2017 con un mapa de los diferentes proyectos de análisis genómicos mundiales.
Sin embargo, analizando el mapa, tanto África como Asia (excepto China), están de color gris, lo que significa que hay muy poca información sobre su genoma. Por eso, hay un par de proyectos que están intentando secuenciar la población de esas zonas: el H3Africa y el GenomeAsia 100k. En estos estudios se pone de manifiesto que un 80% de los datos genómicos disponibles son europeos mientras que tan solo el 10% son asiáticos y el 2% son africanos.
Como podemos ver en la figura 3, esto supone un grave problema de infrarrepresentación genómica. Esto implica que, cuando se calcula la puntuación de riesgo poligenético o poligene score ( un tipo de estudio que, en base al análisis de las mutaciones que tienen las células de una persona, indica cuál es la probabilidad de sufrir alguna enfermedad como el alzheimer, ictus, diabetes tipo 1, etc.), los resultados sean tan fiables como lanzar una moneda al aire. Por eso, cuantos menos datos disponibles, más difícil utilizarlos y que sean fieles a la realidad.

Figura3. Las barras de colores son la distribución de población por razas y en la curva que hace pendientes representa cuántos estudios se han hecho progresivamente de una tecnología que se llama GWAS. Hay una desproporción entre lo que es la población y de lo que tenemos información.
Compartir los datos: ¿Cuál es la situación en Europa?
En el 2018, se reurieron los ministros de 14 países diferentes en el #DigitalDay y acordaron que en 2022 compartirían un millón de genomas con datos clínicos entre todos los países firmantes, España incluida. En la comunidad científica que estaba trabajando en tema, había dudas sobre la factibilidad de esa afirmación: no había infraestructura, ni financiación, ni genomas, ni datos clínicos compartidos, y mucho menos entre países.
Como se esperaba, a finales del 2022, no se consiguió el hito. En lugar de secuenciar un millón de genomas, juntaron 500,000 genomas de proyectos ya realizados y 500,000 genomas provenientes del Genome of Europe. Genomas, que se utilizan como referencia genómica europea. En este contexto, a finales de 2022, la comisión europea creó el proyecto Billion One Million Genomes para financiar y poner en marcha el Genomics Data Infrastructure, para llevar a cabo los objetivos de 2018, con fecha límite en 2027.
A nivel español, existe el proyecto IMPaCT, que pretende dar respuestas a preguntas y necesidades de los científicos y científicas. ¿Cómo? Estableciendo una plataforma y las reglas de cómo se puede utilizar la genómica en la medicina personalizada en el Sistema Nacional de salud. Por ejemplo, un investigador que ha detectado una mutación en uno de sus pacientes que padece microcefalia, le interesa saber si se ha detectado esa misma mutación relacionada con la misma enfermedad y con la misma frecuencia en otra población, para estudiarla. La idea es que la red europea le proporcioné (o no) acesso a esos datos (en caso de haberlos) junto a un cuestioniario previo para conocer el usuario, su proyecto y para qué necesita esos datos.
Los beacon, un escaparate genómico
Sin embargo, para llegar a este punto de pedir los datos que interesan al investigador, debe poder saber que hay datos que le interesan en el dataset. Y este es el objectivo de la plataforma desarrollada por Global Alliance Health, Beacon: compartir datos de mutaciones genéticas de forma pública.
Por ejemplo, si una persona quiere comprarse unos zapatos rojos, tiene dos opciones: puede ir a un gran centro comercial y buscar zapatos rojos en todas las tiendas de zapatos del centro o puede entrar en Google y poner zapatos rojos. Google informará de qué tiendas con zapatos rojos hay a su alrededor, pero no indicará el stock que hay, tamaños, qué tipo de zapatos, etc; solo orienta. Pues el beacon funciona como un escaparate virtual, te deja ver qué zapatos hay, pero sin saber nada sobre las interioridades de la tienda (donde están hechos, donde se compran, material, etc.). Así pues, volviendo a las mutaciones géneticas, la gran ventaja de Beacon es que no enseña esa información sensible relativa al paciente, aunque se debe tener en cuenta que es muy difícil anonimizarla al 100%.
De hecho, ya hay una versión 2 del proyecto Beacon, que intenta modelar no solo las mutaciones genéticas sino también el contexto clínico, que es el modelo llamado genómica clínica.

Figura 4. El modelo de Beacon versión 2.
Además, el proyecto permite crear redes de beacons, que facilitan aún más compartir datos entre hospitales, centros de investigación o instituciones relacionadas con la salud. De momento, este proyecto es la forma más segura de compartir información más o menos pública, aunque no significa que sea anónima.
A modo de resumen, aun hay mucha reticencia a compartir datos, y en particular datos genómicos. Francis Collins decía en un artículo: “Es ilusorio pensar que estamos anonimizados en el aspecto genómico” y realmente, la única forma de estar en paz es saber que ni tus datos genómicos ni los de nadie lo están.
Referencias
- Skloot, Rebecca (2012). La vida inmortal de Henrietta Lacks. Editorial: Booket.
- Modelo Beacon V2: https://beacon-project.io/
- Modelos de cesión de datos para la investigación médica
